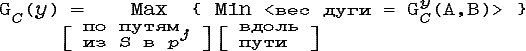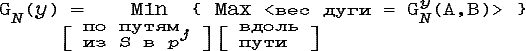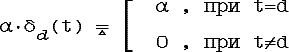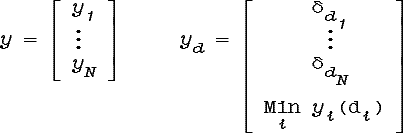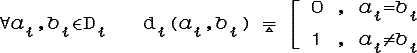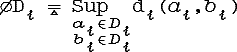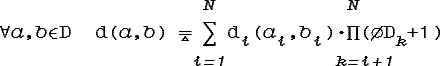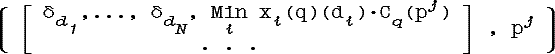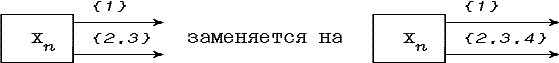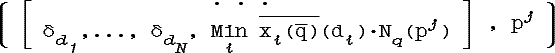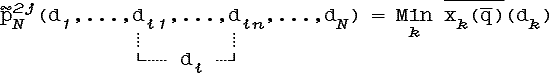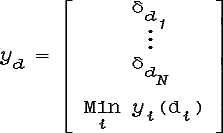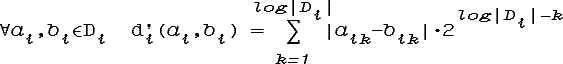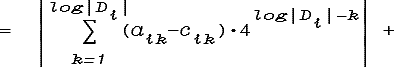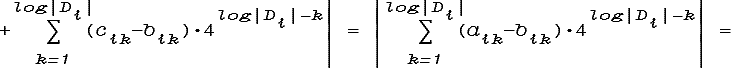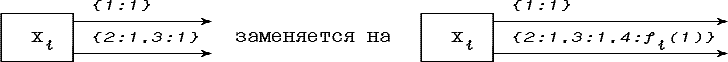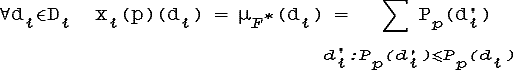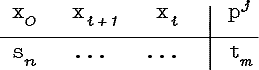![]()
Fuzzy graph-schemes in pattern recognition © 1992 Dmitry A.Kazakov
4. Нечеткие граф-схемы
Для решения задачи нечеткого обучения мы будем использовать аппарат нечетких граф-схем.
4.1. Нечеткие графы и граф-схемы
В этом разделе будет обобщено на нечеткий случай понятие граф-схемы. В 4.1.1. дается определение нечеткой граф-схемы. Далее в 4.1.2. рассматривается поведение граф-схемы как решающего правила. Доказывается эквивалентность граф-схемы и «образов классов», введенных в разделе 3.3. (Теорема 4.1.1). Показывается аддитивность граф-схемы по объединению (Теорема 4.1.2) и условие доминирования возможности над необходимостью при использовании граф-схем (Теорема 4.1.3). В 4.1.4. предлагается метод приведения нечеткой граф-схемы к каноническому виду (с четкими дугами) и доказывается соответствующая теорема (Теорема 4.1.4).
Граф Бержа [Оре80]
вводится как бинарное
отношение над множеством вершин E
- G:E![]() E→{0,1}.
Две вершины A,B
E→{0,1}.
Две вершины A,B![]() E
графа G
связаы дугой тогда и
только тогда, когда
G(A,B)=1.
E
графа G
связаы дугой тогда и
только тогда, когда
G(A,B)=1.
Нечеткий граф Бержа [Коф82]
естественным образом
обобщает понятие четкого графа.
Нечеткий граф Бержа есть
нечеткое бинарное отношение над множеством
вершин E -
G:E![]() E→[0,1].
Совершенно очевидно,
что нечеткий граф
представляет собой нечеткое множество над E2.
E→[0,1].
Совершенно очевидно,
что нечеткий граф
представляет собой нечеткое множество над E2.
Определим композиции нечетких отношений:
R:E1
E2→[0,1], S:E2
![]() -композиция:
S
-композиция:
S![]() R:E1
R:E1![]() E3→[0,1]
E3→[0,1]
E1
В [Коф82] рассматривается º-композиция, аналогичная приведенной нами
-композиции.
![]() -композиция:
S
-композиция:
S![]() R:E1
R:E1![]() E3→[0,1]
E3→[0,1]
Очевидно, что
Введем обозначение для r-раз
![]() и
и ![]() -композиций
нечеткого отношения R (легко
видеть, что
-композиций
нечеткого отношения R (легко
видеть, что ![]() и
и ![]() -композиции
ассоциативны по отношению к самим себе):
-композиции
ассоциативны по отношению к самим себе):
При этом,
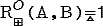
Путем T, длины r в нечетком графе G называется
последовательность вершин:
T={Ai},
где Ai![]() E,
а i=0,..,r.
E,
а i=0,..,r.
С путем T можно связать пару величин:
и
В [Коф82] CG(T) называется силой пути Т. По аналогии, NG(T) можно назвать слабостью пути.
Ясно, что
и NG(T)
![]() CG(T).
CG(T).
Можно ввести
понятия сильнейшего и слабейшего
путей из вершины A в вершину B длины r.
Сильнейший путь ![]() из A в B длины rесть такой путь, что для любого другого пути T той
же длины CG(
из A в B длины rесть такой путь, что для любого другого пути T той
же длины CG(![]() )
)
![]() CG(T).
Аналогично,
CG(T).
Аналогично, ![]() -
слабейший путь, если NG(
-
слабейший путь, если NG(![]() )
)
![]() NG(T).
Отметим, что в дополнении
графа G
NG(T).
Отметим, что в дополнении
графа G ![]() и
и ![]() меняются местами:
меняются местами:
![]() (
(![]() )
)
![]()
![]() (T)
и
(T)
и ![]() (
(![]() )
)
![]()
![]() (T).
(T).
В [Коф82] доказывается замечательный результат:
Аналогично:
Транзитивными замыканиями нечеткого отношения G называются
нечеткие отношения G![]() и G
и G![]() ,
определяемые как
,
определяемые как
В силу монотонности и ограниченности ![]() и
и ![]() G
G![]() и G
и G![]() всегда существуют.
всегда существуют.
Легко убедиться, что для любых двух вершин A и B существуют сильнейший TC и слабейший TN пути такие, что:
CG(TC) = G
(A,B)
Действительно, при длине пути, большей
числа паросочетаний вершин графа, отрезки
пути начинают повторяться, не внося
дальнейшего вклада в силу или слабость пути.
То есть существует такое r, что ![]() t>r
t>r
![]() и
и ![]() .
.
4.1.1. Нечеткие граф-схемы
Четкие граф-схемы рассматриваются в работах [Тан74, Бл87, Орл82]. Мы обобщим понятие граф-схемы применительно к теории возможностей и теории нечетких множеств.
Рассмотрим функцию,
ставящую в
соответствие каждому вектору y![]()
![]() из пространства
нечетких описаний N признаков
нечеткий граф G
из пространства
нечетких описаний N признаков
нечеткий граф G![]() с вершинами из
множества E:
с вершинами из
множества E:
G
:E
Причем, потребуем выполнения следующих условий.
1. Множество вершин E состоит из N+1 непересекающихся подмножеств:
Каждое Ei
при i![]() N
соответствует признаку xi:
вершины из Ei «проверяют»
признак xi. Множество E1 состоит из одной
вершины S: E1={S}.
EN+1 есть
множество классов: EN+1={pj}.
N
соответствует признаку xi:
вершины из Ei «проверяют»
признак xi. Множество E1 состоит из одной
вершины S: E1={S}.
EN+1 есть
множество классов: EN+1={pj}.
2. При любом значении
y![]()
![]()
a. Вершина S - начальная:
![]() A
A![]() E
G
E
G![]() (A,S)=0;
(A,S)=0;
b. Дуги, исходящие из Ei
(i![]() N)
входят в вершины
N)
входят в вершины ![]() Ek:
Ek:
k
G
c. Вершины {pj} - конечные
Таким образом, G
3. Вес дуги, исходящей из вершины
A![]() Ei
(i
Ei
(i![]() N)
и входящей в вершину B
N)
и входящей в вершину B![]() E,
определяется
некоторым нечетким множеством pAB
E,
определяется
некоторым нечетким множеством pAB![]() [0,1]Di,
связываемым с A и B:
[0,1]Di,
связываемым с A и B:
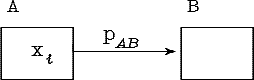
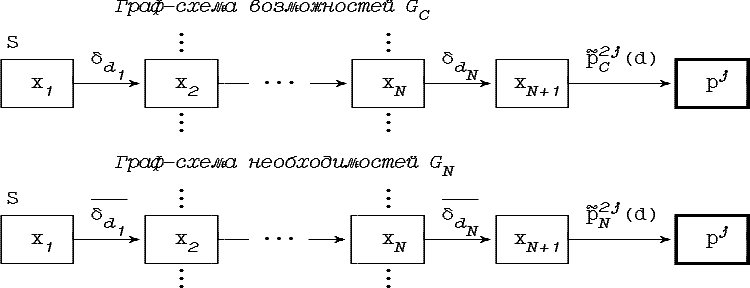
Подобную функцию мы будем называть нечеткой граф-схемой возможностей и изображать в виде графа с вершинами, связанными взвешенными величинами pAB дугами, как показано на рис. 4.1.
Рис. 4.1. Дуга граф-схемы
Нечеткая граф-схема необходимостей вводится,
как функция, ставящая в
соответствие y![]()
![]() нечеткий граф G
нечеткий граф G![]() ,
дополнение которого
удовлетворяет перечисленным выше условиям.
Т.е.
дополнение нечеткой
граф-схемы необходимостей есть нечеткая
граф-схема возможностей,
веса дуг которой
являются дополнениями весов
соответствующих дуг в исходной граф-схеме.
,
дополнение которого
удовлетворяет перечисленным выше условиям.
Т.е.
дополнение нечеткой
граф-схемы необходимостей есть нечеткая
граф-схема возможностей,
веса дуг которой
являются дополнениями весов
соответствующих дуг в исходной граф-схеме.
Граф-схемой вообще, мы будем называть пару нечетких граф-схем - возможностей и необходимостей:
G = { GC ; GN} :
} .
Мы будем говорить, что дуга в граф-схеме возможностей отсутствует, если ее вес - пустое подмножество Di: pAB=Ø. Аналогично, в граф-схеме необходимостей дуга опускается, если ее вес есть Di.
Можно отметить аналогию, между граф-схемой возможностей и электрической схемой, составленной из сопротивлений, с одной стороны, и, между граф-схемой необходимостей и электрической схемой из проводимостей, с другой.
4.1.2. Граф-схема, как решающее правило
Рассмотрим
транзитивные замыкания нечетких графов G![]() и G
и G![]() при фиксированном y
при фиксированном y![]()
![]() :
:
(G
G
(G
G
Можно ввести решающее правило G:![]() →
→![]() 2:
2:
По теореме о сильнейшем пути (см.[Коф82]):
Теорема 4.1.1. (доказательство)
такие, что
q.e.d.
Очевидно, что
справедливо и обратное утверждение,
т.е.
по любым {![]() }
и {
}
и {![]() }
можно построить
соответствующую им граф-схему.
}
можно построить
соответствующую им граф-схему.
Таким образом,
граф-схема полностью
описывается нечеткими множествами {![]() }
и {
}
и {![]() }.
Где
}.
Где ![]() можно рассматривать
как верхнюю оценку классифицирующим
правилом G образа
класса pj.
Аналогично,
можно рассматривать
как верхнюю оценку классифицирующим
правилом G образа
класса pj.
Аналогично,
![]() - нижняя оценка.
- нижняя оценка.
Теорема 4.1.2. (доказательство)
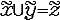
GC(x)
Теорема 4.1.3. (доказательство)
GN(y)
GC(y)
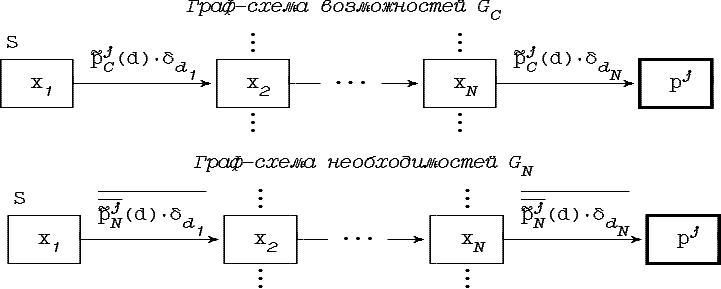
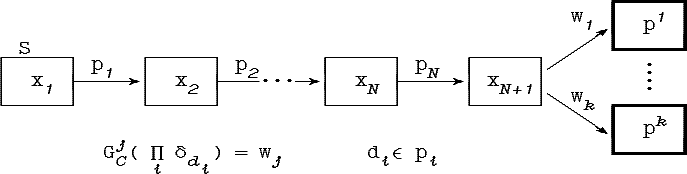
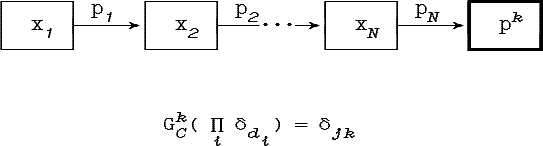
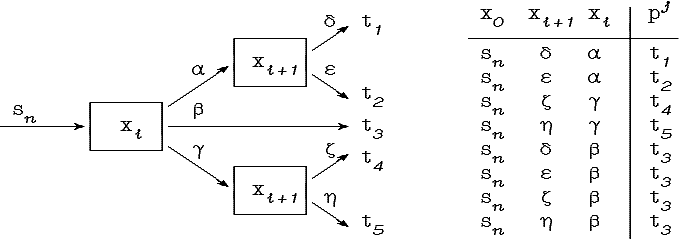
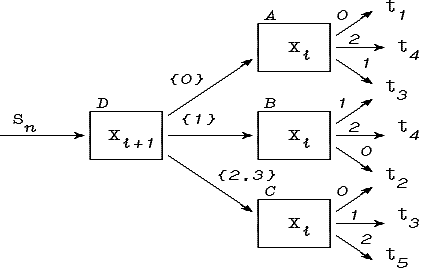
Решающее правило типа «перечисления»
может быть представлено в виде граф-схемы,
для которой каждой точке d![]() D
и каждому классу pj
соответствует в граф-схемах
возможностей и необходимостей путь из
начальной вершины S в
вершину класса pj
(см.
рис.
4.2.).
D
и каждому классу pj
соответствует в граф-схемах
возможностей и необходимостей путь из
начальной вершины S в
вершину класса pj
(см.
рис.
4.2.).
Рис. 4.2. Граф-схемы эквивалентные правилу типа «перечисления»
Здесь α·δd обозначает точечное нечеткое множество вида:
Так как вдоль данного пути в граф-схеме возможностей
![]()
то
Аналогично для граф-схемы необходимостей:
![]()
4.1.3. Граф-схемы и нечеткие деревья решений
Нечеткие деревья
решений широко используются в теории
распознавания и классификации [Cha77].
Нечеткое дерево
решений - это функция, ставящая
в соответствие вектору значений нечетких
признаков y![]() [0,1]N
нечеткий граф
определенного вида (обычно,
дерево),
веса дуг которого
есть координаты вектора y.
[0,1]N
нечеткий граф
определенного вида (обычно,
дерево),
веса дуг которого
есть координаты вектора y.
Граф-схемы, с одной стороны, обобщают нечеткие деревья решений, так как веса дуг определяются более сложными функциями значений нечетких признаков. С другой стороны, граф-схема порождает пару нечетких графов: граф возможностей, собирающий свидетельства PRO и граф необходимостей, дополнение которого собирает свидетельства CONTRA.
Ценой определенного усложнения любая граф схема может быть преобразована в пару нечетких деревьев решений, что мы сейчас и продемонстрируем.
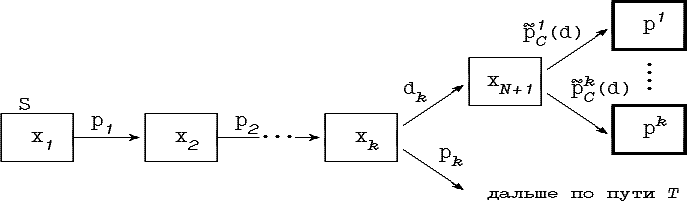
4.1.4. Граф-схемы с четкими дугами
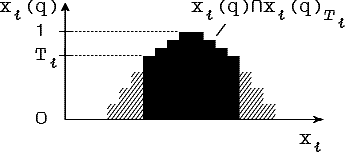
Дугу граф-схемы возможностей GC, проверяющую i-й признак (см. рис. 4.3.) мы будем называть четкой, если pC - точечное четкое подмножество Di, т.е.
Рис 4.3. Дуга граф-схемы, проверяющая i-й признак
Для четкой дуги
Аналогично, дугу pN граф-схемы необходимостей мы будем называть четкой, если ее дополнение - точечное четкое подмножество Di:
и, следовательно:
Если все дуги граф-схемы - четкие,
то очевидно,
что GC
и ![]() суть нечеткие деревья
решений.
суть нечеткие деревья
решений.
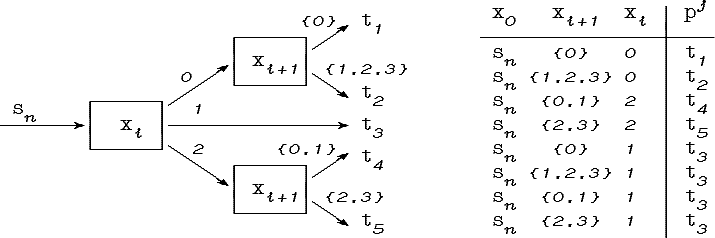
Рассмотрим процедуру преобразования обучающего множества L1 к такому виду, что правило типа «перечисления» будет допускать реализацию в виде нечетких деревьев решений.
Построим обучающее множество L2, в котором каждому обучающему примеру из L1 будет соответствовать усеченный обучающий пример вида:
Усечение обучающих примеров до уровня T позволяет сократить количество дуг граф-схемы. Так как
и
то следовательно L1
![]() L2.
Введем теперь
вырожденный признак xN+1,
принимающий лишь одно
значение 1 (т.е.
DN+1={1}).
Построим граф-схему в
которой для каждого d
L2.
Введем теперь
вырожденный признак xN+1,
принимающий лишь одно
значение 1 (т.е.
DN+1={1}).
Построим граф-схему в
которой для каждого d![]() D
пути в класс pj
примут вид,
показанные на рис. 4.4.
D
пути в класс pj
примут вид,
показанные на рис. 4.4.
Рис. 4.4. Дуги четкой граф-схемы
Так как
и
то ![]() и
и ![]() , т.е.
, т.е.
L2
~ L3,
а значит,
L1 ![]() L3.
В построенных граф-схемах
возможностей и необходимостей все дуги,
проверяющие признаки x1,x2,...,xN
- четкие,
признак xN+1
L3.
В построенных граф-схемах
возможностей и необходимостей все дуги,
проверяющие признаки x1,x2,...,xN
- четкие,
признак xN+1![]() 1,
следовательно GC
и дополнение GN
могут быть
представлены нечеткими деревьями решений.
1,
следовательно GC
и дополнение GN
могут быть
представлены нечеткими деревьями решений.
Классифицируемые объекты также могут быть преобразованы к виду, когда первые N признаков задаются четкими множествами, а вся нечеткость сводится в N+1-й признак.
Для объекта y![]()
![]() построим множества yd
построим множества yd![]()
![]() 3
для d
3
для d![]() D:
D:
![]()
Следовательно:
т.е. имеет место следующая теорема
Теорема 4.1.4. (доказательство)
Таким образом, первые N слоев граф-схемы, проверяющие признаки с первого по N-й могут быть четкими, что существенно упрощает программную реализацию.
4.2. Обучение
В данном разделе будет рассмотрена задача нечеткого обучения с учителем. Предлагается метрика для нечеткого аналога правила ближайшего соседа и рассматриваются свойства соответствующего классификатора (Теоремы 4.2.1 и 4.2.2). Далее в 4.2.1. предлагается алгоритм построения нечеткой граф-схемы, реализующей данный классификатор.
Как уже отмечалось ранее, по обучающему множеству L можно построить верхнюю и нижнюю оценки классов pj:
и
![]() (d)
есть возможность принадлежности
точки d образу
класса pj.
С этой точки зрения
обучение есть увеличение
(d)
есть возможность принадлежности
точки d образу
класса pj.
С этой точки зрения
обучение есть увеличение ![]() в соответствии с
некоторыми априорными знаниями о структуре
образа класса. Т.е.
цель обучения -
восполнение неполноты обучающего
множества, покрывающего
не все возможные ситуации.
в соответствии с
некоторыми априорными знаниями о структуре
образа класса. Т.е.
цель обучения -
восполнение неполноты обучающего
множества, покрывающего
не все возможные ситуации.
В [Экс87] рассматриваются следующие цели обучения:
- Расширение круга решаемых задач
- Выдача более точных результатов
- Получение ответов с меньшими затратами
- Упрощение уже имеющихся знаний
Так как априорная
информация о классах носит,
обычно
предположительный (возможностный) характер,
то увеличение ![]() вряд ли оправдано,
ведь
вряд ли оправдано,
ведь ![]() (d)
- необходимость принадлежности
d образу
класса pj
.
(d)
- необходимость принадлежности
d образу
класса pj
.
Можно представить себе случай, когда априорная информация имеется не тоько о классах, но и о их дополнениях - обучение на отритцательных примерах. Тогда
Для общности
рассуждений рассмотрим набор порогов {Ti},
где каждый порог Ti![]() [0,1]
соответствует
некоторому признаку xi.
Пусть теперь a
- некоторая точка из
области значений признаков D.
[0,1]
соответствует
некоторому признаку xi.
Пусть теперь a
- некоторая точка из
области значений признаков D.
Мы будем говорить, что a представлено в обучающем множестве L, если
q
Множество представленных в L элементов D мы будем обозначать как DL:
Теорема 4.2.1. (доказательство)
Как мы уже отмечали ранее, целью обучения является увеличение множества образов классов таким образом, чтобы оно покрывало все точки D. Иными словами, необходимо изменить поведение классифицирующего правила в точках непредставленных в обучающем множестве.
Метризуем множество значений признаков D. Пусть области значений каждого из признаков xi метризованы и di- соответствующие метрики. Если «естественного» расстояния для значений признака xi нет, то можно ввести такую метрику:
Пусть ØDi- диаметр Di:
Тогда метрика D может иметь вид:
Аксиомы рассстояния:
1. d(a,b) = 0
![]()
![]() i
di(ai,bi)
= 0
i
di(ai,bi)
= 0 ![]()
![]() i
ai=bi
i
ai=bi
![]() a=b
a=b
2. d(a,b) = d(b,a) ![]()
![]() i d(ai,bi)
= d(bi,ai)
i d(ai,bi)
= d(bi,ai)
3. d(a,b) ![]() d(a,c) + d(c,b)
d(a,c) + d(c,b) ![]()
![]() i di(ai,bi)
i di(ai,bi)
![]() di(ai,ci)+di(ci,bi)
di(ai,ci)+di(ci,bi)
Построим множество ![]() следующим образом:
следующим образом:

т.е. ![]() b
b![]() DL
d(a,å)
DL
d(a,å)
![]() d(a,b). Можно
сказать, что
d(a,b). Можно
сказать, что
![]() - наилучшее в смысле d
продолжение
множества
- наилучшее в смысле d
продолжение
множества ![]()
![]() DL
на все D.
DL
на все D.
Теорема 4.2.2. (доказательство)
и
при равных Ti
Очевидно, что
если все пороги Ti=0,
то ![]() =
=![]() ,
т.е.
обучение отсутствует.
Вообще смысл порога Ti
состоит в указании
наименьшего уровня возможности
принадлежности точек области значений
признака xi
классам.
,
т.е.
обучение отсутствует.
Вообще смысл порога Ti
состоит в указании
наименьшего уровня возможности
принадлежности точек области значений
признака xi
классам.
4.2.1. Алгоритм построения нечеткой граф-схемы
Рассмотрим, как строится граф-схема возможностей по обучающему множеству L.
Алгоритмы построения четких граф-схем можно найти в [Тан74, Орл82, Бл87].
1. Заменим в
обучающем множестве величины xi(q)
на xi(q)![]() xi(q)Ti
, как показано на рис.
4.5.
xi(q)Ti
, как показано на рис.
4.5.
Рис. 4.5. Усечение обучающего примера
2. Построим новое обучающее множество с четкими обучающими примерами, как мы это делали в предыдущем разделе. В этом множестве каждому обучающему примеру из L будет соответствовать
новых примеров вида:
где часть, соответствующая необходимостям нас не интересует, т.к. мы будем строить граф-схему возможностей, и
Если задача обучения содержит взвешенные обучающие примеры (4º'), то возможность того, что данный обучающий пример относится к классу pj умножается на Min:
3. В качестве конечных узлов граф-схемы избираются классы pj. Далее обучающее множество последовательно свертывается по количеству признаков от n=N+1 до n=0.
4. Во множестве обучающих примеров выделяются классы эквивалентности, состоящие из примеров, первые n-1 значений признаков которых совпадают.
5. При n=N+1 для каждого класса эквивалентности строится узел с дугами, ведущими в классы, взвешенными наибольшими значениями признака xN+1 для данного класса.
6. При n![]() N
возможны следующие
варианты:
N
возможны следующие
варианты:
a. Все обучающие примеры из класса эквивалентности соответствуют одному классу. В этом случае ничего не делается.
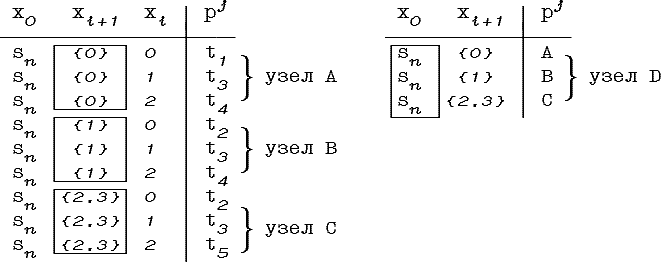
b. Для каждого класса строится дуга, исходящая из нового узла. Веса всех дуг - объединение значений признака xn для всех обучающих примеров, входящих в класс эквивалентности. Если некоторые точки Dn (области значений признака xn) не покрываются объединением весов дуг, то эти точки включаются в веса дуг, ближайших к ним по метрике dn. Т.е. выбирается ближайшая точка из Dn, в которой функция принадлежности веса некоторой дуги не 0. В эту дугу и включается непокрытая точка, причем, значение функции принадлежности которой в этой точке принимается равным значению в ближайшей к ней точке. Например, если Dn={1,2,3,4}, то результат такой операции будет соответствовать, показанному на рис. 4.6.
Рис. 4.6. Преобразование дуг граф-схемы
Узлы с одинаковыми дугами, проверяющие один и тот же признак, объединяются. Эта операция превращает граф-схему в граф более общего вида нежели дерево.
7. Строится новое обучающее множество, в котором каждому классу эквивалентности соответствует один обучающий пример пример с n-1 признаком. В качестве классов новым обучающим примерам назначаются либо реальные классы, либо сгенерированные узлы. Новое обучающее множество непротиворечиво и содержит n-1 признак. Далее мы переходим к пункту 4.
Граф-схема необходимостей строится аналогичным образом:
1. Усечение обучающих примеров:
2. Новое обучающее множество:
3. pj- конечные узлы
4. Выделяются классы эквивалентности
5. При n=N+1 строится узел с дугами, взвешенными наибольшими значениями признака xN+1.
6. Если обучение по отрицательным примерам не требуется, то узел генерируется в любом случае. Дуги взвешиваются дополнениями объединений значений признака xn. В противном случае, действия те же, что и для алгоритма построения граф-схемы возможностей, за исключением того, что покрытие всех возможных значений признака соответствует не равенству объединения весов дуг Dn, на равенству Ø их пересечения.
7. Строим новое обучающее множество и переходим к пункту 4.
Формально говоря, граф-схема необходимостей строится в точности так же, как и граф-схема возможностей, за исключением того, что веса всех дуг, кроме тех, что исходят из узлов, проверяющих признак xN+1, инвертируются.
4.3. Преобразование исходных данных
В данном разделе рассматриваются различные вопросы, связанные с преобразованием признаков. В 4.3.1. предлагается бинаризовать признаки, а в 4.3.2. излагаются необходимые изменения алгоритма построения нечеткой граф-схемы в случае бинаризации линейно-упорядоченных признаков: вводится понятие линейно-упорядоченного нечеткого признака, рассматривается метрика для правила ближайшего соседа, сохраняющая полезные свойства упорядоченных шкал, и доказываются соответствующие теоремы (Теоремы 4.3.1 и 4.3.2). Далее, в 4.3.3. предлагается эмпирический метод модификации правила ближайшего соседа.
4.3.1. Бинаризация признаков
Последовательность проверки граф-схемой признаков чрезвычайно сильно влияет на результат обобщения. Это видно из метрики d, в которой первый признак перевешивает все остальные. Далеко не всегда информативность признаков расходится столь сильно. Чаще признаки почти равноправны. Одним из примеров такой ситуации является евклидова метрика области значений признаков. Бинаризация позволяет сгладить неравноправность признаков.
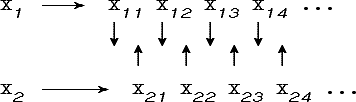
Рассмотрим признак xi с областью значений Di. Так как Di конечно, мы можем занумеровать все элементы Di. При этом, если Di упорядочено, то желательно, чтобы номера элементов Di следовали этому порядку. Введем n=log|Di| новых признаков: xi1, xi2,.., xin. Причем, xik представляет собой k-й разряд двоичного представления номера значения признака xi:
где #di-
порядковый номер di![]() Di,
[·] - операция взятия
целой части.
Di,
[·] - операция взятия
целой части.
Очевидно,
что подпространство
признака xi:
![]() i
эквивалентно
подпространству описаний признаков {xik}:
i
эквивалентно
подпространству описаний признаков {xik}:
xi:[0,1]Ω→[0,1]Di
xik:[0,1]Ω→[0,1]Dik , где Dik={0,1}
Таким образом, признак xi можно заменить набором двоичных подпризнаков {xik} следующим образом:
и
будет эквивалентно
и
Классифицируемый объект y![]()
![]() ,
как и ранее
преобразуется ко множеству почти четких yd:
,
как и ранее
преобразуется ко множеству почти четких yd:
каждое из которых, с учетом бинаризации признака xi примет вид:
Если обучения для необходимостей не предполагается, то бинаризация их не имеет особого смысла.
В силу эквивалентности обучающих множеств бинаризацию можно проводить для всех признаков. Поэтому для того, чтобы сделать признаки x1 и x2 более или менее равноправными их, можно бинаризовать и перемешать полученные бинарные признаки:
4.3.2. Линейно-упорядоченные признаки
Если множество значений признака xi обладает
естественным линейным порядком, т.е. ![]() a,b,c
a,b,c![]() Di
Di
1. a
![]() a
a
2. a ![]() b
b ![]() a
a ![]() a = b
a = b
3. a ![]() b
b ![]() c
c ![]() a
a ![]() c
c
4. a ![]() b V a
b V a ![]() b , то
b , то
такой признак мы будем называть линейно-упорядоченным. Область значений Di линейно-упорядоченного признака xi является шкалой порядка [Хан78].
Операция бинаризации признака xi вводит на Di метрику d'i:
которая может не совпадать с естественной метрикой di в том смысле, что точки, ближайшие по di и d'i к некоторой другой точке Di, могут оказаться различными. Например, если Di есть натуральные числа {1,2,3,4,5}, то согласно d'i 1 ближе к 5, чем к 4:
d'i(1,5) = d'i(0012,1012) = 4 < 5 = d'i(0012,1002) = d'i(1,4).
Если считать, что метрика линейно-упорядоченного признака должна быть согласована с отношением порядка, т.е.
bi
то требование совпадения естественой метрики и метрики бинаризованных признаков можно ослабить до требования согласованности последней с отношением порядка.
Такой согласованной метрикой является d*i:
.
Прежде всего покажем, что d*i действительно удовлетворяет аксиомам расстояния:
1. d*i(ai,bi)
= 0 ![]() ai=bi
ai=bi
2. d*i(ai,bi) = d*i(bi,ai)
3. d*i(ai,ci) + d*i(ci,bi) =
= d*i(ai,bi)
Теорема 4.3.1. (доказательство)
Для произвольного подмножества Ai
Ai, если åi
1. åi совпадает с ai в наибольшем числе первых бинарных признаков (разрядов) xik.
2. Если первый несовпадающий разряд ain= 0, то среди разрядов åin+1, åin+2,... наибольшее число первых нулей.
3. Если ain= 1, то среди åin+1, åin+2,... наибольшее количество единиц.
Теорема 4.3.2. (доказательство)
ai
Требование согласованности не обеспечивает совпадения метрик di и d*i, но согласно доказанной теореме гарантирует, что
ai
Таким образом, бинаризация линейно-упорядоченного признака с учетом метрики d*i не слишком сильно изменит характер обучения. Применение более сильных шкал, например шкалы интервалов [Хан78], видимо слишком ограничивает эффективность обучения. Кроме того, методы классификации для евклидовых пространств признаков достаточно хорошо разработаны [Хан78, Фук79, Ту78].
Рассмотрим те изменения, которые следует внести в алгоритм построения граф-схемы для реализации метрики d*i. На шаге 6.a алгоритма узел не генерировался, что приводило к тому, что значение признака, который мог бы проверяться этим узлом, никак не учитывалось. Если этот признак xin порожден бинаризацией линейно-упорядоченного признака xi, мы теперь будем генерировать узел при условии, что xin не покрывает всей области своих значений ({0,1}), и если в подграфе с вершиной в этом узле присутствуют узлы, проверяющие хотя бы один из признаков xin+1, xin+2,..., т.е. бинарных признаков, порожденных признаком xi. Причем, возможны два варианта, в зависимости от значения признака xin:
xin(q)=0 , тогда дуга с весом 0 ведет в подграф с вершиной в данном узле, а дуга с весом 1 в тот же подграф, то с подставленными в качастве значений признаков xin+1, xin+2,... единицами.
xin(q)=1 , тогда дуга с весом 1 ведет в этот подграф, а дуга с весом 0 в него же, но с подставленными нулями вместо значений xin+1, xin+2,...
Данные изменения обеспечивают согласно теореме 4.3.1 реализацию граф-схемой метрики d*i при условии, что порядок проверки признаков xin+1, xin+2,... не изменяется.
4.3.3. Граф-схема как наилучшее продолжение
Как уже отмечалось выше алгоритм построения граф-схемы обеспечивает включение непредставленных в обучающем множестве точек области значений признаков в ближайшие к ним образы классов. При этом, значение функции принадлежности включаемой точки заимствуется у ближайшей к ней точки образа класса.
Можно усовершенствовать алгоритм построения граф-схемы таким образом, чтобы значение функции принадлежности включаемой точки уменьшалось в зависимости от ее удаленности от образа класса (т.е. ближайшей к ней точки образа класса).
Предположим, что fi-
убывающая функция расстояния di
такая, что fi(0)=1,
а fi(![]() )=0.
Тогда на шаге 6 алгоритма
построения граф-схемы, когда некоторые
значения признака xi
не покрываются дугами,
следует включать эти значения в веса дуг со
значениями функции принадлежности,
домноженными на fi
от расстояния между
значением и дугой. Например, если Di={1,2,3,4},
то дуга будет преобразована, как показано
на рис. 4.7.
)=0.
Тогда на шаге 6 алгоритма
построения граф-схемы, когда некоторые
значения признака xi
не покрываются дугами,
следует включать эти значения в веса дуг со
значениями функции принадлежности,
домноженными на fi
от расстояния между
значением и дугой. Например, если Di={1,2,3,4},
то дуга будет преобразована, как показано
на рис. 4.7.
Pис. 4.7. Преобразование дуги граф-схемы
Здесь {2:1,3:1,4:fi(1)} обозначает нечеткое множество с функцией принадлежности, принимающей значения 0 в 1, 1 в 2 и 3, fi(1) в 4. Точка 4 включена в дугу со значением функции принадлежности 1·fi(4-3), где 1 - значение функции принадлежности в точке 3 - ближайшей к 4 точке Di.
Граф-схема, полученная с помощью данного алгоритма уже не будет четкой для признаков x1,...,xN, однако при преобразовании классифицируемого объекта к четкому виду классификация остается поиском пути в четком графе.
4.3.4. Преобразование вероятностных данных
Часто бывает так,
что значения признака xi
задаются в виде
распределения вероятности. Т.е. в качестве
исходных данных мы располагаем функцией Pi(·|p).
Где Pi(·|p)
есть условное распределение вероятности над множеством
значений признака xi
нечеткого события p.
Иначе говоря, ![]() di
di![]() Di
Pi({di}|p)=Pp(di)
- вероятность того, что признак xi
принимает значение di
на нечетком событии p.
Величины Pp(di)
могут быть получены,
например, как относительные частоты
появления значений di
или методами
статистического оценивания.
Di
Pi({di}|p)=Pp(di)
- вероятность того, что признак xi
принимает значение di
на нечетком событии p.
Величины Pp(di)
могут быть получены,
например, как относительные частоты
появления значений di
или методами
статистического оценивания.
В подобных случаях
перед нами стоит задача получения по Pp
образов нечетких
событий p и
![]() .
Или, другими словами, задача построения
функции распределения возможности по
функции распределения вероятности. Этот
вопрос рассматривается в [Дю90,
Бор89],
поэтому мы изложим
лишь основной результат.
.
Или, другими словами, задача построения
функции распределения возможности по
функции распределения вероятности. Этот
вопрос рассматривается в [Дю90,
Бор89],
поэтому мы изложим
лишь основной результат.
В качестве
распределения возможностей xi(p)
можно взять нечеткое
множество ![]() F*
[Дю90]:
F*
[Дю90]:
А в качестве распределения необходимостей
[Дю90]:
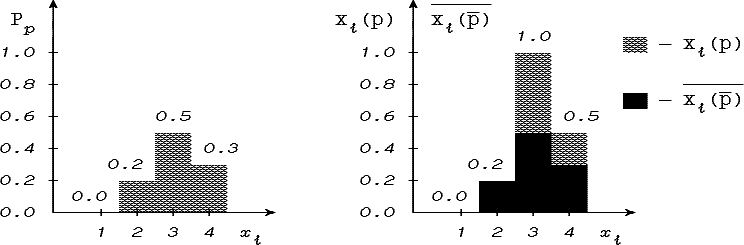
Например (рис. 4.8.), если множество значений признака есть Di={1,2,3,4}, а Pp(1)=0, Pp(2)=0.2, Pp(3)=0.5, Pp(4)=0.3.
Рис. 4.8. Преобразование распределения вероятностей в распределение возможностей и необходимостей
4.3.5. Получение возможностей из экспертного опроса
Существует обширная литература, посвященная вопросу построения функции принадлежности нечеткого множества по данным опроса экспертов [Яг86, Мел90, Мал91]. Мы изложим лишь простейший способ получения xi(p), так как в большинстве приложений признаки оцениваются без участия человека.
Пусть n экспертов утверждают, что значение di признака xi реализуется на предъявленном им нечетком событии p, а m экспертов придерживаются противоположного мнения, тогда можно принять, что
Аналогичным образом эксперты
опрашиваются и по поводу ![]() .
.
4.3.6. Предобработка исходных данных
Исходные признаки часто имеют непрерывные области значений. В этом случае, а так же, когда мощность области значений слишком велика, необходимо выполнить дискретизацию области значений признака. Подобного рода предобработка является типичной задачей кластеризации [Кла80]. Целесообразно, в данном случае, применять наиболее простые алгоритмы кластеризации, например гистограммные методы или методы, описываемые в [Каз88а, Каз88б], так как основная задача предобработки - понижение мощности пространства описаний с наименьшими потерями в разделимости классов. Эта задача может оказаться достаточно трудной для зависимых признаков, когда границы кластеров становятся подвижными. Интересным, в таких случаях, представляется применение техники нечеткого кластер анализа [Bez91]. При этом область значений признака покрывается набором нечетких интервалов - аналогов фокальных элементов теории Демпстера-Шейфера, а одно и тоже значение признака может входить с различными степенями уверенности в несколько интервалов-кластеров.
Проблема предобработки усложняется, когда значения признаков случайны. Постановка задачи нечеткого обучения подразумевала, что неопределенность значения признака оценивалась источником, из которого это значение поступало. Типичный пример, когда человека просят определить на глаз высоту дерева, а он отвечает - «метров десять», что предполагает некоторый нечеткий интервал с центром в точке десять. Иная ситуация возникает, когда признаком является, например, масть выпавшей карты. Если распределение плотности вероятности априорно известно, то оно может быть преобразовано к распределению возможностей, описанным ранее способом. Однако, чаще всего, его приходится оценивать по обучающей выборке, что весьма не просто сделать в условиях зависимости признаков, малого объема выборки и неизвестных априорных вероятностях классов. Наиболее простым выходом из подобной ситуации является оценка вероятностей принадлежности классам только для тех обучающих примеров, которые встречаются в обучающем множестве несколько раз, входя при этом в различные классы. В предположении равных априорных вероятностей классов, все совпадающие по дискретизованным значениям обучающие примеры, заменяются на один новый пример, в котором вероятности его принадлежности классам приравниваются относительным частотам их появления в замещаемом наборе примеров. Далее это распределение вероятностей преобразуется к распределению возможностей и необходимостей обычным способом.
4.4. Дообучение
В данном разделе будет рассмотрена проблема дообучения с использованием нечетких граф-схем. Предлагается алгоритмы дообучения и изменения порядка проверки признаков граф-схемой.
Реальная обучающаяся система существует в некотором временнóм интервале, в течение которого возможно появление новых обучающих примеров, хотя бы в силу ограниченности машинных ресурсов, не позволяющих обрабатывать обучающие множества слишком большого размера. Существуют и другие причины, по которым желательно предусмотреть возможность дообучения. Отметим, что в данном случае, речь пойдет только о дообучении, но не о переобучении. Разница между которыми состоит в том, что при дообучении считается, что классы и признаки не претерпели изменений по прошествии времени с момента последнего вмешательства в систему, т.е. новые обучающие примеры могут отвергать лишь обобщения, сделанные на основе предыдущего обучающего множества, но не его само. При переобучении допускается изменение классов и признаков и, соответственно, возможно отвержение ранних обучающих примеров.
В качестве исходных данных дообучения выступает новое обучающее множество L и граф-схема G, построенная по старому обучающему множеству.
Пусть некотрое d
представлено в L.
Тогда L задает
для такого d распределение
возможностей и необходимостей его
принадлежности классам pj:
![]() (d)
и
(d)
и ![]() (d),
где
(d),
где
взяты из правила типа «перечисления», построенного по L.
С другой стороны, G некоторым образом классифицирует точечные множества
причем имеет место следующая ситуация
Задача дообучения - устранить данное противоречие.
Рассмотрим граф-схему возможностей GC. При данном d существует единственный путь в четкой ее части, проверяющей признаки с x1 по xN. Возможны две ситуации:
1. Признак xN+1 проверяется при классификации (рис.4.9.)
Рис.4.9. Путь, проверяющий признак xN+1
2. Признак xN+1 не проверяется (рис. 4.10.)
Рис.4.10. Путь, не проверяющий признак xN+1
Таким образом, при фиксированном d граф, получаемый из граф-схемы возможностей не ветвится вплоть до проверки признака xN+1. Пусть неветвящаяся часть пути есть T, а его длина r. Рассмотрим два случая:
r=N-1,
т.е. вдоль пути T проверяются
все признаки, от x1
до xN.
Следовательно, их значения в старом
обучающем множестве нам известны - это
веса дуг p1,
p2,...
И ![]() i di
i di![]() pi
- di
входит в дугу.
pi
- di
входит в дугу.
r<N,
т.е. часть признаков не проверяется.
Предположим, что значения непроверяемых
признаков были тем или иным способом
сохранены. Если среди непроверяемых
признаков есть хотя бы один xk
такой, что dk![]() Dk,
это означает, что d не
было представлено в старом обучающем
множестве. В этой ситуации нужно найти
наибольшее k при
котором dk
Dk,
это означает, что d не
было представлено в старом обучающем
множестве. В этой ситуации нужно найти
наибольшее k при
котором dk![]() Dk
(т.е. как можно дальше
отойти от корня граф-схемы), создать на
пути T узел,
проверяющий признак xk
и присоединить к
нему узел, проверяющий вырожденный
признак xN+1
(рис. 4.11.).
Dk
(т.е. как можно дальше
отойти от корня граф-схемы), создать на
пути T узел,
проверяющий признак xk
и присоединить к
нему узел, проверяющий вырожденный
признак xN+1
(рис. 4.11.).
Рис. 4.11. Модификация пути граф-схемы
Если же для всех i di![]() pi,
то d было
представлено в старом обучающем множестве.
Следовательно, исходя из принципа
дообучения, необходимо изменить веса дуг
узла, проверяющего признак xN+1,
в ситуации 1 или
создать таковой в 2.
Причем вес дуги, ведущей в класс pj
- wj
корректируется
следующим образом:
pi,
то d было
представлено в старом обучающем множестве.
Следовательно, исходя из принципа
дообучения, необходимо изменить веса дуг
узла, проверяющего признак xN+1,
в ситуации 1 или
создать таковой в 2.
Причем вес дуги, ведущей в класс pj
- wj
корректируется
следующим образом:
wj = max [wj,
Следует ометить, что если через изменяемый узел проходят кроме T другие пути, то необходимо создать для них его неизмененную копию. Линейная упорядоченность признаков при создании нового узла должна учитываться обычным образом.
Проделав эту операцию для всех d, представленных в новом обучающем множестве, следует объединить совпадающие узлы, просмотрев все новые и измененные узлы.
Граф-схема необходимостей корректируется тем же способом, за исключением того, что веса дуг корректируются в сторону уменьшения:
wj = min [wj,
Рассматривая работу данного алгоритма для обучающего множества, состоящего из единственного точечного обучающего примера, можно убедиться в справедливости нижеследующей теоремы.
Теорема 4.4.1.
Граф-схема, полученная при помощи дообучения, не отличается от граф-схемы, построенной по обучающему множеству - объединению старого и нового обучающих множеств.
4.4.1. Селекция признаков
Результат обучения в очень большой степени зависит от порядка проверки признаков. Общим правилом является желательность проверки признаков в порядке убывания их информативности [Орл82]. Задача определения информативности признаков по обучающей выборке чрезвычайно сложна даже в том случае, когда признаки суть случайные величины.
Поэтому вместо строгого определения понятия информативности признака разумно воспользоваться эмпирическими характеристиками сложности граф-схемы. Такими как:
и.т.п. А для их оптимизации применить технологию экспертных систем.
Важным вопросом, в этой связи, становится задача изменения порядка проверки признаков. Трудно сказать, что является менее накладным с точки зрения расходов машинного времени - построение новой граф-схемы по старому обучающему множеству, с учетом изменения порядка проверки признаков, или корректировка уже существующей ее версии.
4.4.2. Изменение порядка проверки признаков
Рассмотрим случай, когда необходимо изменить порядок проверки признаков xi и xi+1 на обратный. Имея данную операцию в качестве примитива, мы можем получить произвольную последовательность проверки признаков.
Поскольку алгоритм сходен для граф-схем возможностей и необходимостей, рассмотрим только первую из них.
Выделим в граф-схеме возможностей часть, проверяющую признаки xi и xi+1 (рис. 4.12.).
Рис. 4.12. Часть граф-схемы возможностей
Сразу исключим из рассмотрения те входящие дуги, которые сразу ведут в узлы, проверяющие признак xi+1, и те, на пути по которым после проверки признака xi не делается проверка xi+1.
Рассмотрим пути, начинаемые оставшимися входящими дугами. Например, рассмотрим часть граф-схемы, показанную на рис. 4.13.
Рис. 4.12. Часть граф-схемы, подлежащая преобразованию
Построим обучающее множество в котором дуги t1...tl играют роль классов, а новый признак x0 принимает значения из s1...sk. Каждый путь по sn в tm в новом обучающем множестве получает обучающие примеры, приведенные на рис. 4.14.
Рис. 4.14. Обучающее множество для преобразования граф-схемы
В которых в качестве значений признаков xi и xi+1 стоят веса соответствующих дуг. Если признак xi+1 не проверяется на пути по sn в tm, то остальные обучающие примеры для путей по sn дополняются примерами с соответствующими значениями xi и pj. Например, рассмотрим часть граф-схемы. приведенную на рис. 4.15.
Рис. 4.15. Пример преобразования граф-схемы
Так как δ![]() ε=ζ
ε=ζ![]() η=Di+1,
то непосредственное построение по новому
обучающему множеству обновленной части
граф-схемы приведет к пересекающимся
весам дуг: δ
η=Di+1,
то непосредственное построение по новому
обучающему множеству обновленной части
граф-схемы приведет к пересекающимся
весам дуг: δ![]() ζ
ζ![]() Ø
V δ
Ø
V δ![]() η
η![]() Ø,
что нежелательно. Поэтому по δ,
ε, ζ, η следует построить порождающие
элементы {λk}
такие, что с помощью
их объединений можно получить δ,...,η.
Делать это нужно для каждой уникальной
дуги sn. Далее каждый
обучающий пример расщепляется на
соответствующее число новых обучающих
примеров по количеству λk
входящих в вес дуги
из узла, проверяющего признак xi+1.
Например, если Di+1={0,1,2};
Di={0,1,2,3}
и то λk
для {0},{1,2,3},{0,1},{2,3}
есть {0},{1},{2,3}.
Соотвествующая граф-схема,
обучающее множество и процесс построения
эквивалентной ей граф-схемы с другим
порядком проверки признаков приведены на
рис. 4.16.
Ø,
что нежелательно. Поэтому по δ,
ε, ζ, η следует построить порождающие
элементы {λk}
такие, что с помощью
их объединений можно получить δ,...,η.
Делать это нужно для каждой уникальной
дуги sn. Далее каждый
обучающий пример расщепляется на
соответствующее число новых обучающих
примеров по количеству λk
входящих в вес дуги
из узла, проверяющего признак xi+1.
Например, если Di+1={0,1,2};
Di={0,1,2,3}
и то λk
для {0},{1,2,3},{0,1},{2,3}
есть {0},{1},{2,3}.
Соотвествующая граф-схема,
обучающее множество и процесс построения
эквивалентной ей граф-схемы с другим
порядком проверки признаков приведены на
рис. 4.16.
Рис. 4.16. Конкретная граф-схема
В итоге мы получим новую часть граф-схемы возможностей, приведенную на рис. 4.17.:
Рис. 4.17. Новая граф-схема возможностей
Процесс изменения граф-схемы необходимостей проходит таким же образом, за исключением того, что λk строятся как набор множеств, позволяющий получать веса дуг путем их пересечений, а не объединений, как в случае граф-схемы возможностей.
4.5. Пример построения нечеткой граф-схемы возможностей
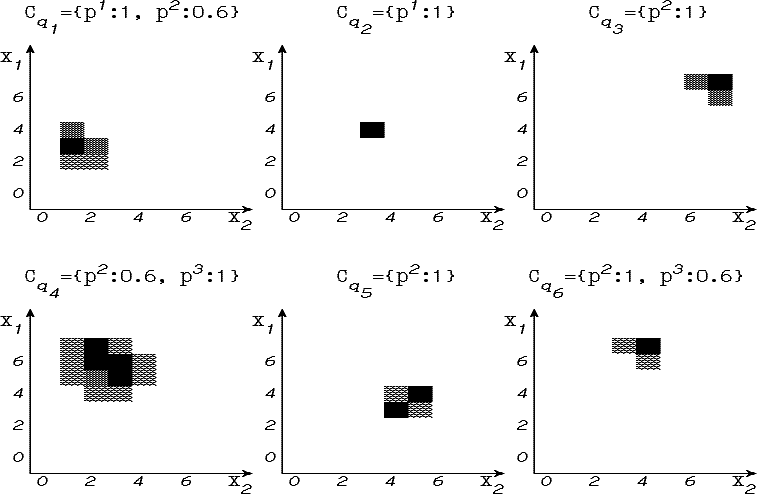
Пусть обучающее множество содержит шесть обучающих примеров: q1,...,q6. Для каждого из которых задано нечеткое множество x(qi) над областью значений двух линейно-упорядоченных признаков: x1 и x2, принимающих значения из {0,1,...,7}. Кроме того, для каждого обучающего примера задано распределение возможностей принадлежности его трем классам: p1, p2 и p3 - Cq. Мы изобразим это графически (рис. 4.18.):
Рис. 4.18. Обучающее множество
Здесь степени принадлежности данной точки области значений признаков обозначены яркостями (рис. 4.19.):
Рис. 4.19. Уровни принадлежности
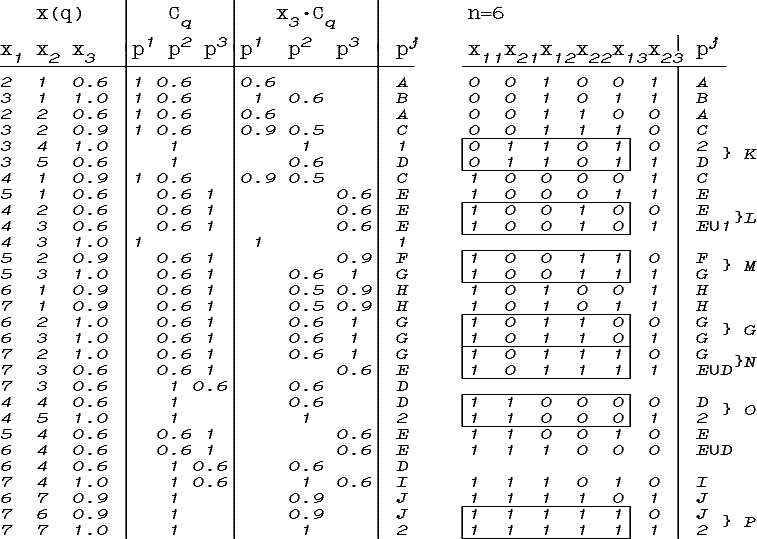
Признаки x1 и x2 мы бинаризуем: x1→x11x12x13; x2→x21x22x23 и перемешаем полученные признаки, таким образом, что они будут проверяться в последовательности: x11x21x12x22x13x23. Для того, чтобы привести задачу к стандартному виду, введем дополнительный признак x3 с областью значений {1}, и приведем обучающее множество к четкому по признакам xij виду. В качестве порога T выберем 0.5.
В представленной на рис. 4.20. таблице в первом столбце находятся обучающие примеры нового обучающего множества. Во втором столбце - распределение возможностей принадлежности обучающего примера классам. В третьем - веса дуг узлов граф-схемы, проверяющих признак x3, равные произведению возможности принадлежности данного обучающего примера классу, в который ведет дуга, на возможность принадлежности данной точки области значений признаков x1, x2 обучающему примеру. В четвером - метки соответствующих узлов. На рис. 4.20. показан так же первый шаг алгоритма построения граф-схемы. На нем слева находится таблица для обучающего множества, справа - ее преобразование на первом шаге алгоритма построения граф-схемы возможностей. Рамками обозначены классы эквивалентности обучающих примеров. Фигурными скобками - соответствующие им названия генерируемых узлов граф-схемы.
Рис. 4.20. Построение граф-схемы (первый шаг)
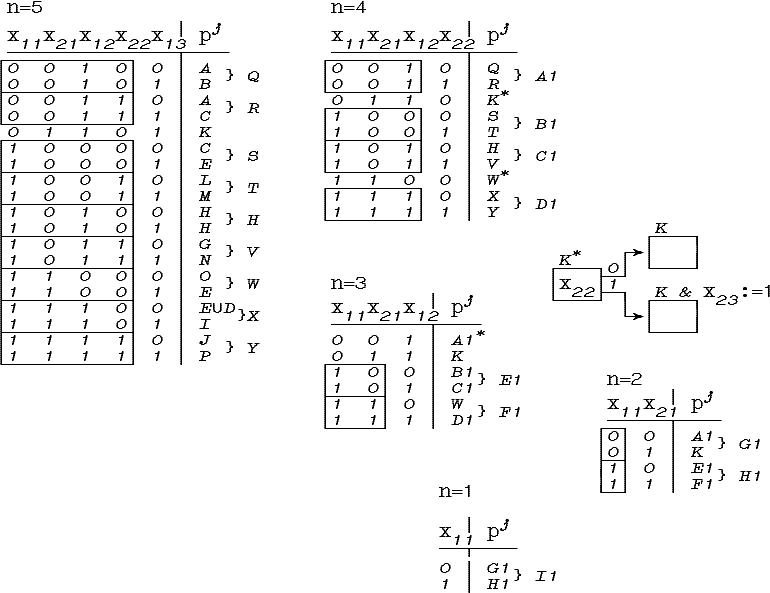
Далее приводится последовательность
выполнения шагов алгоритма построения
граф-схемы возможностей. Квадратными
рамками обведены классы эквивалентностей.
Фигурные скобки указывают на
соответствующие классам эквивалентности
узлы. Звездочкой отмечаются узлы, для
которых требуется учтывать линейную
упорядоченность. Например, узел K,
проверяет признак x23,
но на шаге n=4 проверка
признака x22
не потребовалась,
поэтому при классификации, если x22![]() 0,
то x23
следует считать
равным 1. Последовательность
следующих шагов построения граф-схемы
приведена на рис. 4.21.
0,
то x23
следует считать
равным 1. Последовательность
следующих шагов построения граф-схемы
приведена на рис. 4.21.
Рис. 4.21. Построение граф-схемы
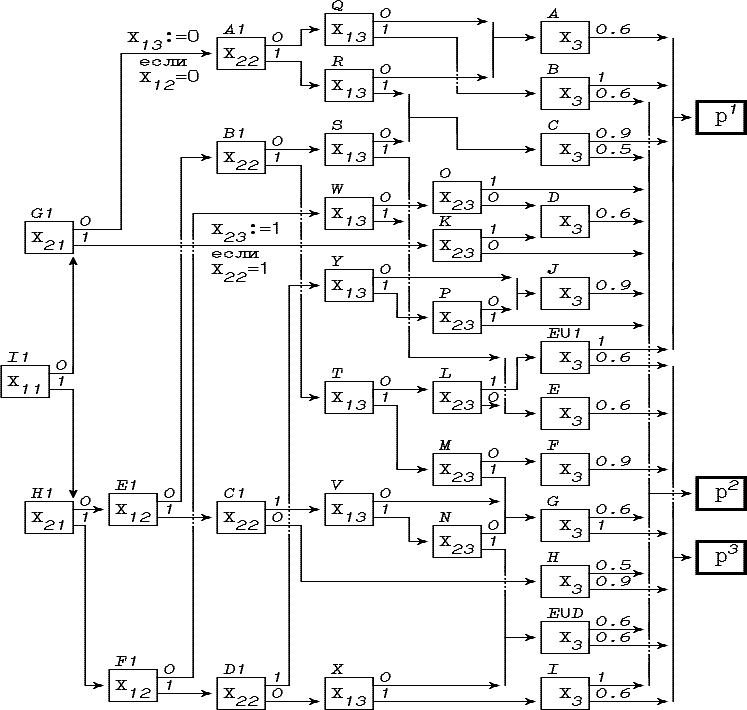
Полученная граф-схема возможностей
содержит 6 четких
слоев, проверяющих признаки x11x21x12x22x13x23,
и один слой, проверяющий вырожденный
признак x3![]() 1.
Результат ее
построения приведен на рис. 4.22.
1.
Результат ее
построения приведен на рис. 4.22.
Рис. 4.22. Граф-схема возможностей
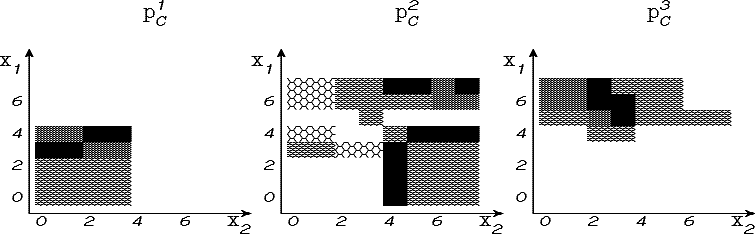
Далее мы приводим результат классификации всех точек области значений признаков, т.е. нечеткие множества p1С, p2С, и p3С, представляющие собой распределение возможностей принадлежности точек области значений признаков классам p1, p2 и p3, соответственно (рис. 4.23.).
Рис. 4.23. Образы классов, порождаемые граф-схемой
Где степени принадлежности точек области значений признаков обозначены яркостями, приведенными на рис. 4.19. Например, точка (4,4) принадлежит p1 с возможностью 1; p2 - 0.6 и p3 - 0.
4.6. Выводы
1. Нечеткие граф-схемы являются удобным средством представления нечетких классификаторов.
2. Для машинной реализации разумно использовать граф-схемы в канонической форме - с четкими дугами.
3. Алгоритм построения граф-схемы реализует нечеткое правило ближайшего соседа.
4. Бинаризация признаков может быть выполнена с сохранением полезных свойств упорядоченных шкал признаков. При этом, признаки могут быть сделаны почти равноправными.
5. Дообучение и изменение порядка проверки признаков могут быть выполнены без полной перестройки граф-схемы.