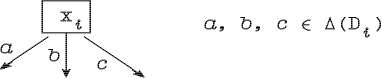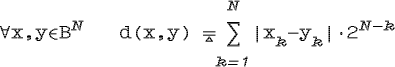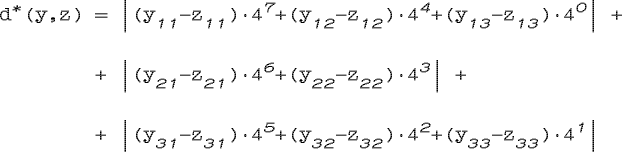![]()
Fuzzy graph-schemes in pattern recognition © 1992 Dmitry A.Kazakov
2. Деревья решений в задачах распознавания
Деревья решений как способ представления классифицирующего правила существуют уже давно. Например, запись решения шахматного этюда есть, фактически, дерево решений. Мы попробуем дать наиболее общее определение нечеткого дерева решений.
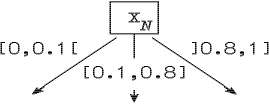
Предположим, имеется набор N признаков, принимающих значения из множеств D1,...,DN , соответственно. Обозначим как xi реализацию i-го признака. В зависимости от конкретного приложения, под xi может пониматься, например, случайная величина или нечеткое подмножество области значений признака. Пусть для каждого i-го признака задано некоторое семейство Δ(Di), каждый элемент которого есть некоторое подмножество Di (возможно нечеткое). Это может быть 2Di - множество всех четких подмножеств Di, или σ-алгебра, если в качестве реализации признака xi рассматривается случайная величина. С каждой вершиной дерева решений связывается один единственный признак. Мы будем говорить, что данная вершина проверяет этот признак. Веса дуг, исходящих из некоторой вершины нечеткого дерева, связанной с i-м признаком, есть элементы Δ(Di) (рис 2.1).
Рис 2.1. Вершина дерева
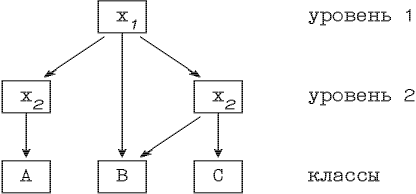
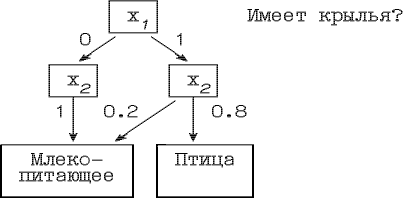
Множество вершин, проверяющих i-й признак мы будем называть i-м уровнем нечеткого дерева решений. В целом нечеткое дерево имеет N+1 уровней. Первый или верхний уровень состоит из единственной вершины - корня дерева. Дуги исходящие из вершин уровня i входят только в нижние по отношению к нему уровни, но никогда не ведут наверх. Дуги предпоследнего уровня N ведут в классы или по-другому - листья дерева, составляющие последний уровень. Например, на рис. 2.2.
Рис 2.2. Пример дерева решений
Следует заметить, что с формальной точки зрения нечеткое дерево решений не является деревом, однако очевидно, что эквивалентное дерево всегда может быть получено, поэтому мы не будем отказываться от общепринятого термина.
Дополнительно
потребуем, чтобы было задано нечеткое
отношение in,
ставящее в соответствие реализации
признака xi
и весу дуги a![]() Δ(Di)
величину xi
in a из
интервала [0,1].
Эта величина выражает степень уверенности
в переходе по дуге с весом a
при данной
реализации признака xi.
Δ(Di)
величину xi
in a из
интервала [0,1].
Эта величина выражает степень уверенности
в переходе по дуге с весом a
при данной
реализации признака xi.
При фиксированных реализациях признаков, заменяя веса дуг на значения соответствующих бинарных отношений in, мы получим некоторый нечеткий N+1 хроматический граф G. Отметим, что часто именно он называется нечетким деревом решений (например в [Cha76]). Таким образом, нечеткое дерево решений ставит в соответствие реализациям признаков нечеткий граф G, т.е. является нечетко-граф-значной функцией.
Пусть теперь на интервале [0,1] заданы коммутативные бинарные операции * и +. Построим нечеткую композицию нечетких бинарных отношений (графов) G: G2=GºG следующим образом. Для любых двух вершин A и B:
, где
E - множество всех вершин нечеткого дерева решений. Если начальная вершина дерева обозначена как S, то нечеткой классификацией объекта, описанного данной реализацей признаков мы будем называть набор величин GN(S,pj), где pj - есть классы (листья дерева). Каждая из величин GN(S,pj) характеризует степень уверенности в том, что данный объект принадлежит классу pj.
Нечеткое дерево решений называется полным, если для каждой вершины, за исключением листьев, веса исходящих из нее дуг покрывают все возможные значения признака, проверяемого данной вершиной. Если ak - дуги, исходящие из вершины, проверяющей i-й признак, то требование полноты можно записать в виде:
Нечеткое дерево решений называется непротиворечивым если веса дуг, исходящих из любой вершины не пересекаются, т.е. если a и b суть веса двух различных дуг одной вершины, то
2.1. Классификация деревьев решений
Введенное нами определение деревьев решений позволяет классифицировать известные их типы по семейству Δ, нечеткому отношению принадлежности in и бинарным операторам * и +.
2.1.1. Классические четкие деревья решений [Хан78, Ту78, Орл82, Бл87]
Δ - 2Di
in - обычная принадлежность
в смысле четких множеств. При этом требуется, чтобы реализациями признаков были только точечные элементы Δ, тогда как веса дуг могут быть множествами.
* - булева конъюнкция &
+ - булева дизъюнкция V
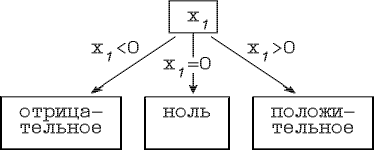
Пример такого дерева приведен на рис. 2.3.
Рис 2.3. Четкое дерево решений
Если четкое дерево решений полно и непротиворечиво, то при любых значениях признаков оно выбирает ровно один класс, т.е. для всех классов, кроме одного значения GN(S,pj)=0, а для последнего 1.
2.1.2. Вероятностные деревья решений [Cha76, His88, Geb88, Seg88]
Каждая реализация признака xi представляет собой случайную величину. Это может быть ответ частного классификатора или оценка распределения вероятностей над областью значений признака, полученная источником знаний экспертной системы и т.п.
Δ - σ-алгебра
in - вероятность принадлежности: a in b = P(a
b)
* - стандартное произведение
+ - стандартное сложение
В вероятностных деревьях решений всегда используются требования полноты и непротиворечивости, имеющие вероятностную интерпретацию. События, соответствующие переходам по дугам, исходящим из данной вершины, составляют полную группу событий. Следствием этого является то, что при любом значении признака xi:
т.е. сумма вероятностей переходов составляет 1. Если, дополнительно, реализации признаков как случайные величины статистически независимы, то:
И, следовательно нечеткая классификация будет обладать свойством:
, где
x - составная случайная величина (x1,x2,...,xN).
Следует отметить,
что требование независимости признаков
является обязательным для применимости
операторов * и
+ из-за
того, что: равенство
P(A![]() B)=P(A)*P(B)
справедливо лишь для
независимых, а P(A
B)=P(A)*P(B)
справедливо лишь для
независимых, а P(A![]() B)=P(A)+P(B)
для непересекающихся
событий A и
B.
B)=P(A)+P(B)
для непересекающихся
событий A и
B.
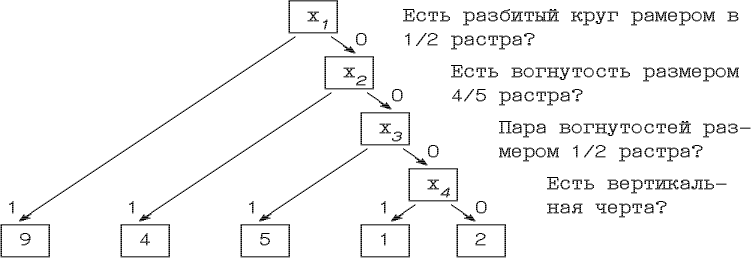
Приведем пример нечеткого вероятностного дерева для распознавания рукописных цифр из работы [Cha77] (см. рис. 2.4.). Каждая реализация признаков x1, x2, x3, x4 представляет собой совокупность случайных величин, оцениваемых системой выделения линий изображения. Например, при P(x1=1)=0.4, P(x2=1)=0.4, P(x3=1)=0.9, P(x4=1)=0.2, мы получим распределение вероятностей классов: '1':0.01, '2':0.03, '4':0.24, '5':0.32, '9':0.4.
Рис. 2.4. Дерево решений для распознавания рукописных цифр
2.1.3. Четкие вероятностные деревья [Атт65, Орл82, Car87]
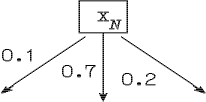
Часто используются деревья у которых первые N-1 уровней четки, а последний уровень, проверяющий N-й признак - нечеток. При этом полагается, что N-й признак распределен равномерно на интервале [0,1], а дуги, исходящие из узлов, его проверяющих, имеют веса, образующие разбиение интервала [0,1] на подинтервалы. Например, как на рис. 2.5.
Рис. 2.5. Узел последнего уровня дерева решений
Так как N-й признак вырожден, т.е. его реализация не меняет своего распределения, можно заранее определить величины xN in aj=|aj|. Поэтому обычно веса дуг, исходящих из такого узла изображаются сразу в виде |aj|, в нашем случае, как показано на рис. 2.6.
Рис. 2.6. Упрощенная форма изображения узла
Величины |aj| принимаются равными вероятностям появления соответствующего класса при условии, задаваемом реализациями признаков. Таким образом, четкое вероятностное дерево решений реализует байесовский классификатор [Ту78]. Пример четкого вероятностного дерева показан на рис. 2.7.
Рис. 2.7. Четкое вероятностное дерево
Вероятностные деревья решений в настоящее время применяются пожалуй наиболее широко, однако перечисленные выше требования делают их использование затруднительным в тех случаях, когда признаки существенно взаимозависимы.
2.1.4. Возможностные деревья (max-min деревья) [Cha76, Коф82]
Δ - [0,1]Di - множество нечетких подмножеств Di
in - нечеткая принадлежность: a in b = C(b|a), т.е. возможность b при условии a. Где a,b
* - операция min
+ - операция max
Требование полноты
используется не всегда, но может быть
выражено в виде: ![]() xi нормального
xi нормального
т.е. одна из дуг ak, проверяющих i-й признак,всегда возможна, при условии нормальности реализации признака (т.е. когда ее функция принадлежности достигает единицы).
Требование непротиворечивости обычно не используется, так как теория возможностей допускает вложенные элементарные события. В отличие от вероятностных деревьев, признаки не обязаны быть независимыми (в смысле теории возможностей [Дю90]), так как всегда справедливо:
C(A
B) = max [C(A),C(B)] и C(A
B)
min [C(A),C(B)].
Таким образом, нечеткое дерево решений всегда выдает верхнюю оценку для условных возможностей принадлежности объекта классам:
GN(S,pj)
C(pj | x1 x2 ... xN)
2.1.5. Деревья необходимостей (min-max деревья)
Δ - [0,1]Di - множество нечетких подмножеств Di
in - нечеткая принадлежность: a in b = N(b|a), т.е. необходимость b при условии a.
* - операция max
+ - операция min
Дерево необходимостей является дополнительным понятием по отношению к дереву возможностей. Оно дает нижнюю оценку:
GN(S,pj)
2.2. Обучение с использованием деревьев решений
Деревья решений, помимо удобного представления решающих правил, обеспечивают мощный аппарат для обучения. Вопрос обучения с использованием деревьев решений рассматривался еще в [Хан78]. Удобство деревьев решений объясняется легкостью введения расстояния на дереве и простотой интерпретации дерева решений человеком.
Деревья решений используются, в основном, для представления так называемых логических алгоритмов распознавания [Гор85, Гор89, Лб81]. Интерес к логическим алгоритмам часто бывает вызван недостатком априорной информации о классах и признаках, не позволяющем применить методы статистического распознавания [Фук79]. К тому же, последние могут быть неприменимы в силу не вероятностного поведения системы, нечеткости признаков и т.п.
Среди логических алгоритмов, не основанных на деревьях решений, следует упомянуть алгоритмы АВО (алгоритмы, основанные на вычислении оценок), предложенные Ю.И.Журавлевым [Жур74, Гор85, Гор89], и близкий к ним метод ГЕКОНАЛ [Геп85], обладающие важным свойством равноправия признаков. Однако, алгоритмы, связанные с деревьями решений, в настоящий момент пожалуй наиболее широко распространены. Обзор такого рода алгоритмов можно найти в работе [Лб81]. Из современных практических работ, основанных на деревьях решений следует упомянуть [Car87, Pat87, Geb88]. Близкими к деревьям решений являются алгоритмы, использующие граф-схемы [Орл82, Бл87]. Граф-схемы охватывают более широкий класс граф-значных функций, каковыми являются деревья решений. Но в практике распознавания они эквивалентны. Все же мы не будем отказываться от термина граф-схемы для того, чтобы подчеркнуть различие в способах их построения.
Недостатком логических алгоритмов является их жесткое поведение и невозможность использования в процессе обучения противоречивых данных. Вот почему представляется интересным использование техники четких вероятностных деревьев в логических алгоритмах [Орл82, Car87, Geb88]. При этом, сущетвует некоторое противоречие - отказавшись от статистических методов распознавания в пользу логических, мы тем не менее пытаемся дать деревьям решений вероятностную интерпретацию. В связи с активным развитием теории нечетких множеств и теории возможностей интересно было бы обобщить логические методы распознавания с позиций теории возможностей, а не вероятностей.
2.3. Четкие граф-схемы в задачах распознавания
Рассмотрим алгоритм
построения граф-схемы решающего правила в
случае четких бинарных признаков и четких
классов в соответствии с [Бл87].
В этом случае,
обучающее множество
имеет вид таблицы Lij,
в i-й
строке которой находятся значения бинарных
признаков, начиная
со значения признака ![]() и т.д.
до значения признака
и т.д.
до значения признака ![]() .
Последним в строке
находится номер класса, соответствующего
данному обучающему примеру.
В качестве начальных
узлов граф-схемы выбираются узлы,
соответствующие
классам. Далее
выделяются пары строк таблицы такие,
что значения первых N-1
признаков совпадают:
.
Последним в строке
находится номер класса, соответствующего
данному обучающему примеру.
В качестве начальных
узлов граф-схемы выбираются узлы,
соответствующие
классам. Далее
выделяются пары строк таблицы такие,
что значения первых N-1
признаков совпадают:
![]() при k<N.
Каждая такая пара
порождает одну строку в новой обучающей
таблице:
при k<N.
Каждая такая пара
порождает одну строку в новой обучающей
таблице: ![]() ,
причем в качестве
класса этой строке назначается либо класс,
соответствовавший
обоим строкам старой таблицы,
либо метка вновь
созданного узла граф-схемы,
если им
соответствовали различные классы
,
причем в качестве
класса этой строке назначается либо класс,
соответствовавший
обоим строкам старой таблицы,
либо метка вновь
созданного узла граф-схемы,
если им
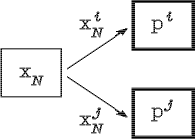
соответствовали различные классы ![]() (см. рис. 2.8.).
(см. рис. 2.8.).
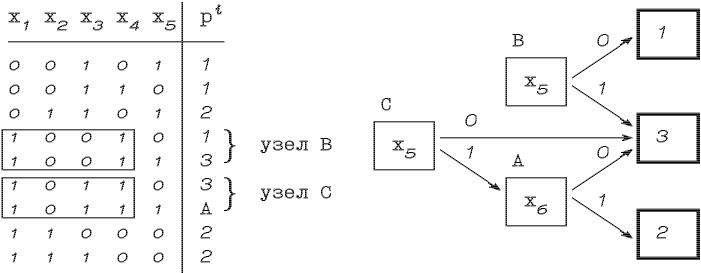
Рис. 2.8. Узел граф-схемы
При порождении новых узлов, узлы с одинаковыми дугами объединяются. Эта операция превращает граф-схему в граф более общего вида нежели дерево [Оре80].
Полученная таким образом таблица будет содержать на один столбец меньше, чем исходная. Повторяя эту операцию еще N-2 раза мы получим искомую граф-схему.
Рассмотрим пример построения граф-схемы (рис 2.9.).
Рис. 2.9. Обучающее множество и выполнение первого шага
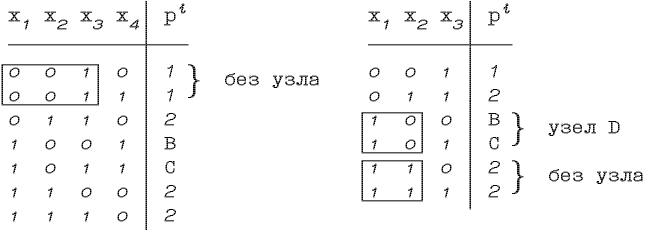
Новая обучающая таблица будет иметь вид, показанный на рис. 2.10.
Рис. 2.10. Дальнейшие шаги построения граф-схемы
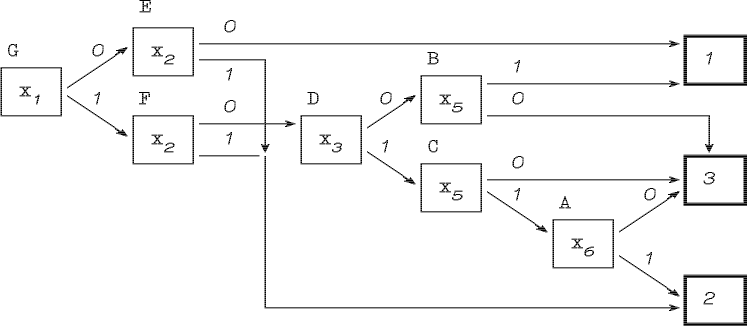
В итоге мы получим граф-схему, приведенную на рис. 2.11.
Рис. 2.11. Граф-схема, построенная по обучающему множеству
Граф-схема - просто
способ представления функции,
отображающей ![]() N
во множество классов {pj},
где
N
во множество классов {pj},
где ![]() N
- пространство
бинарных признаков. Обучающее
множество L есть
функция, отображающая
некоторое подмножество пространства
признаков во множество классов - L:{xi}
N
- пространство
бинарных признаков. Обучающее
множество L есть
функция, отображающая
некоторое подмножество пространства
признаков во множество классов - L:{xi}![]() {pj},
где
{pj},
где
.
Если построенную по L
граф-схему GL
интерпретировать как
функцию, то
GL
есть продолжение L
на все пространство
признаков ![]() N:
GL:
N:
GL:![]() N
N![]() {pj}.
{pj}.
Введем метрику в
пространстве признаков ![]() N
[Бл87]:
N
[Бл87]:
Если теперь рассмотреть работу граф-схемы, то легко убедиться [Бл87], что
Таким образом граф-схема как решающее правило реализует метод ближайшего соседа [Bez81] по метрике d. То есть, при классификации неизвестного вектора признаков z граф-схема относит его к тому же классу, что и класс ближайшего к z вектора из обучающего множества (по метрике d).
В том случае, когда признаки не бинарны, несложно либо модифицировать алгоритм построения граф-схемы [Орл82], либо бинаризовать признаки. В последнем случае возникает проблема сохранения полезных свойств упорядоченных шкал признаков. Подробно этот вопрос рассматривался в работах автора [Геп91а, Геп91б, Геп91в и Gep92]. Ниже приводятся основные результаты.
2.3.1. Линейно-упорядоченные признаки
Если на множестве
значений Di
признака xi
существует
естественное отношение порядка,
т.е.
![]() a,b,c
a,b,c![]() Di
Di
1. a
2. a
a = b
3. a
4. a
и множество классов {pj} так же допускает введение отношения порядка. То если для классификации используется только признак xi, а обучающее множество монотонно, т.е.
ij ( xi
то разумно потребовать, чтобы его продолжение GL было бы так же монотонным. Например, если признак - «рост человека», а классы- «низкий», «средний». и «высокий», то классифицирующее правило должно относить человека более высокого роста, по крайней мере, не к классу более низких людей, чем человека меньшего роста. В этом примере неприятностей можно было бы избежать кластеризовав область значений признака. Однако, во-первых, границы кластеров заранее не известны, собственно, их определение может рассматриваться в качестве цели обучения. Во-вторых, при обобщении на случай нескольких признаков, границы кластеров взаимодействующих признаков становятся функциями их значений. Например, при признаках «вес» и «имеет крылья», если первым проверяется признак «имеет крылья», то вся шкала весов будет зависеть от ответа.
Даже в том случае, когда пространство классов не может быть упорядоченно, можно сформулировать до некоторой степени эквивалентное требование к обучению. Так как упорядочение пространства признаков приводит к упорядочению множества обучающих примеров, а значит порождает некоторую последовательность классов в соответствии с порядком следования обучающих примеров, то разумно потребовать, чтобы произвольный вектор, не входящий в обучающую выборку и находящийся согласно отношению порядка между некоторыми двумя обучающими примерами, относился бы классифицирующим правилом к одному из двух соответствующих им классов.
Далее мы будем
рассматривать те уточнения,
которые следует
ввести в алгоритм построения граф-схемы для
случая нескольких признаков,
упорядоченных в ![]() N
покомпонентным
сравнением. Бинарные
признаки, порожденные
линейно-упорядоченными признаками должны
проверяться в порядке старшинства
соответствующих им разрядов двоичного
представления номера значения
порождающего их линейно-упорядоченного
признака. Кроме
того, на
каждом шаге алгоритма, относящемуся
к такому признаку (xik),
для любого набора
совпадающих строк (в том числе и для одной
единственной строки) в том случае,
когда в описанном
выше алгоритме узел не генерировался,
теперь делать это
можно только тогда, когда
даному набору строк соответствует подграф
уже построенной части граф-схемы,
в котором не
проверяются признаки xi*
- из той же группы,
что и xik.
Например,
когда набору строк
соответствует класс. Во
всех остальных случаях генерируется узел,
проверяющий значение
признака xik.
Причем,
в зависимости от его
значения xjik
в обучающей таблице,
узел будет иметь вид:
N
покомпонентным
сравнением. Бинарные
признаки, порожденные
линейно-упорядоченными признаками должны
проверяться в порядке старшинства
соответствующих им разрядов двоичного
представления номера значения
порождающего их линейно-упорядоченного
признака. Кроме
того, на
каждом шаге алгоритма, относящемуся
к такому признаку (xik),
для любого набора
совпадающих строк (в том числе и для одной
единственной строки) в том случае,
когда в описанном
выше алгоритме узел не генерировался,
теперь делать это
можно только тогда, когда
даному набору строк соответствует подграф
уже построенной части граф-схемы,
в котором не
проверяются признаки xi*
- из той же группы,
что и xik.
Например,
когда набору строк
соответствует класс. Во
всех остальных случаях генерируется узел,
проверяющий значение
признака xik.
Причем,
в зависимости от его
значения xjik
в обучающей таблице,
узел будет иметь вид:


Уточненный таким
образом алгоритм порождает граф-схему G*L,
которая является
продолжением обучающего множества на все
пространоство признаков ![]() N.
При классификации
неизвестного вектора z
N.
При классификации
неизвестного вектора z![]()
![]() N,
G*L
для первого
несовпадающего бинарного признака xik
полагает все
остальные признаки xi*,
порожденные тем же
линейно-упорядоченным признаком,
равными 0
(если zik=0)
или 1 (если
zik=1).
N,
G*L
для первого
несовпадающего бинарного признака xik
полагает все
остальные признаки xi*,
порожденные тем же
линейно-упорядоченным признаком,
равными 0
(если zik=0)
или 1 (если
zik=1).
Можно доказать [Геп91], что метрикой метода ближайшего соседа для построенной таким образом монотонной граф-схемы будет:
, где
индекс i пробегает по признакам xi; индекс k - по бинарным признакам xik, порожденным линейно-упорядоченным признаком xi; nik есть порядковый номер, в соответствии с которым данный признак проверяется граф-схемой. Бинарные признаки могут быть расставлены в произвольном порядке, но с ограничением:
nik>nil
k > l , т.е.
бинарные признаки, порожденные одним линейно-упорядоченным признаком xi должны проверяться в порядке старшинства соответствующих им разрядам двоичного представления номера значения признака xi. Например, если три признака x1, x2 и x3 порождают бинарные признаки: x11, x12, x13, (из x1), x21, x22, (из x2), x31, x32, x33, (из x3), то мы можем расставить их в порядке: x11, x21, x31, x12, x22, x32, x33, x13. Тогда расстояние d* будет иметь вид:
2.4. Выводы
1. Аппарат деревьев решений широко применяется в задачах распознавания. Однако до сих пор первалирует использование вероятностных деревьев решений.
2. Логические алгоритмы обучения, в четком случае, могут быть реализованы на основе граф-схемного подхода к представлению решающего правила.
3. Бинаризация признаков позволяет добиться более глубокого обучения и большей гибкости в вопросе значимости признаков, характерном для стратегии последовательного опроса признаков в, применяемом в деревьях решений и граф-схемах. При этом, возможно сохранение полезных свойств упорядоченных шкал признаков.
4. Таким образом, целесообразно использовать сочетание нечеткого и граф-схемного подходов для решения задачи нечеткого обучения с учителем.